Table of Contents
Functional dependency is a key concept in database design. When designing database relations, it is important to avoid situations that cause update anomalies—problems that occur when changes to data are not properly reflected across all related records. If copies of a relation are not updated consistently, the database can become inconsistent or corrupt.
Another common issue is redundant data. Storing the same information multiple times makes the database complex and increases the risk of update anomalies. Omissions or accidental deletions can also lead to anomalies.
Functional dependencies help in designing robust databases by providing tools such as FD closure, attribute closure, and canonical cover.
These concepts form the foundation for normalization, a process that organizes database relations to reduce redundancy and improve consistency. Normalization is a separate topic, so in this guide, we focus exclusively on understanding functional dependencies in depth.
What is Functional Dependency?
A functional dependency (FD) is a relationship between two sets of attributes in a relation (table). It shows how one set of attributes determines another. A functional dependency is key to designing a relation in database design. The main task of functional dependency is to remove update anomalies.
Before we define a functional dependency , you must understand the difference between the term – relation and table.
Key difference between Relation and Table
| Key Aspect | Relation | Table |
| Definition | Relation is a mathematical and abstract concept from relational theory. | Table is a physical structure that store data in rows and columns. |
| Order of Rows | The rows or tuples have no specific order | The rows have order in storage and retrieval by default. Then ordered if Order By clause is used. |
| Duplicate Rows | No duplicate row – all rows are unique. | Allows duplicate unless Primary key is set to make every row unique. |
| Attribute Names | Must be unique | Must be unique, but aliasing is possible. |
| Null Values | Not part of relational model. | Allowed in table to represent empty or unknown data. |
| Implementation | Rules defined in relational algebra and theory | Use RDBMS softwares like MySQL, Oracle, etc. |
| Schema | Define attributes and domain types | Define the attributes and their data types |
Note that Relation is a mathematical concept that defines the construction of logical structure of tables.
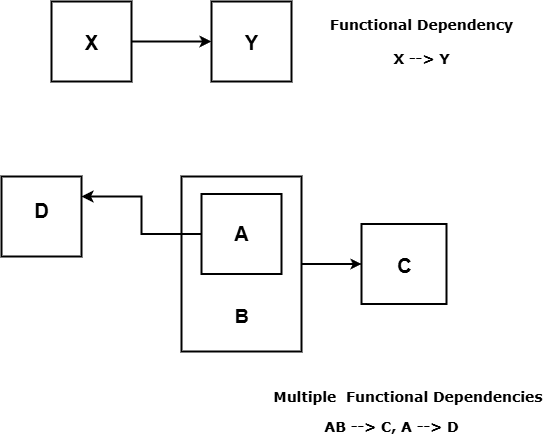
Formal Definition of Functional Dependency
The formal definition of functional dependency, also known as FD is as follows.
“If there is relation schema R with random subset X and Y such that an instance r of R satisfy functional dependency,
FD: X \rightarrow Y
this means for any two tuples t_1 and t_2 in r.
if \space t_1[x] = t_2[x], then \space t_1[y] = t_2[y]
which means Y is functionally dependent on X. In other words, FD: X \rightarrow Y satisfy “uniqueness property”. Every x uniquely determine the value of y.
Determinant and Dependent
In a functional dependency X \rightarrow Y, X is called Determinant and Y is called the Dependent.
Sometimes, an functional dependency does not hold for a relation schema R because the uniqueness property is violated – that is, multiple y values for the same x. Such FDs can be discarded.
The Set of Functional Dependencies
A set of functional dependencies (FDs) is a collection of one or more functional dependencies defined on a relation R.
If relation schema R has attributes, then
F = \{FD_1, FD_2 , ..., FD_n\}where F is the set of functional dependencies and each FD is of the form X \rightarrow Y.
The problem with a large set of FD is that it can bring down the efficiency of the database by adding computational overhead and operational efficiency. The database need to check violation of integrity constraints frequently.
Impact of Large Set of FDs
A large set of functional dependencies can reduce the efficiency of the database by increasing computational overhead. The DBMS must frequently check integrity constraints during insert, update, or delete operations, which can slow down overall performance.
If a set of FDs, F1, exists, we often try to find a smaller set F2 such that every FD in F1 is implied by the FDs in F2. This smaller set is called a minimal cover or canonical cover and helps simplify database design.
Now that you understand functional dependencies, the next step is to classify individual FDs into trivial and non-trivial, an important distinction for normalization and designing efficient database schemas.
There is three ways a functional dependencies closure, F+ help us design databases.
- Help us find the candidate key with attribute closure.
- The FD is basis for checking Normalization for relations.
- The closure of FD, together with attribute closure help us find redundant funcitonal dependencies.
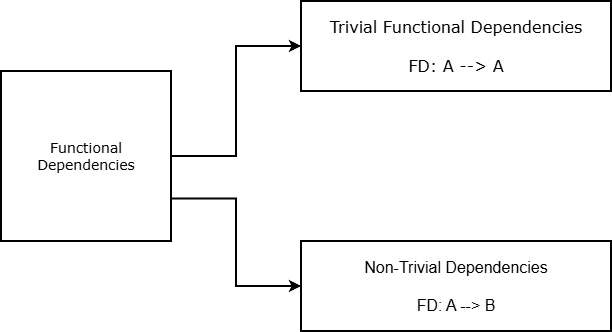
Trivial and Non-Trivial Dependencies
Functional dependencies are classified into trivial and non-trivial dependencies to help reduce unnecessary or unhelpful dependencies. Although trivial dependencies are theoretically correct, they are usually not useful in practical database design.
Formal Definition of Trivial dependencies
A dependency is trivial for X \rightarrow Y if and only if X is subset of Y (Y \subseteq X ).
Examples:
FD_1: A \rightarrow A \space where \space A \subseteq A\\
FD_2: \{A, C\} \rightarrow CIf X and Y are two disjoint sets than functional dependencies between them is non-trivial. Only non-trivial dependencies are considered meaningful and useful in database design.
Closure of Set of Functional Dependencies (FDs)
The closure of set of functional dependencies (FDs) is the process of finding all the possible FDs that hold for a given relation schema R. It is denoted as F+.
The size of the closure, F+ can be large or small, depending on the number of attributes in the relation and number of interdepenent FDs of relation schema R.
Armstrong’s Axioms
For smaller FDs, it is easier to find the closure F^+ by directly listing all the FDs. However, for a huge relation schema, with trivial FDs , non-trivial FD and redundant FDs, closure of F, F^+ will be huge. To find the closure of set of functional dependencies, F^+, we use a set of inference rules called Armstrong’s Axioms.
The three basic axioms are:
- Reflexivity rule
- Augmentation rule
- Transitivity rule
Reflexivity Rule
If \space Y \subseteq X, then \space X \rightarrow Y
The reflexivity rule means that if Y is a subset of X, then the set of attributes, Y functionally dependent on X. In other words, X functionally determines its own subset Y.
Augmentation Rule
If X \rightarrow Y, then \space ZX \rightarrow ZY for \space any \space set \space of \space attributes \space Z
It means we can safely add a set of attriibutes Z to both sides of the FD. The augmentation rule only allows you to add attributes to both sides of a valid FD – it does not gurantee that the reverse it true.
Transitivity Rule
If X \rightarrow Y \space and \space Y \rightarrow Z , then \space X \rightarrow Z
If a set of attributes X determines Y and Y[/katex[ determines [katex]Z, then X functionally determine Z is called the transitivity rule.
These axioms form the basis of finding the closure of FD and we can also derive additional inference rule from these 3 basic axioms.
Additional Inference Rules (Derived from Armstrong's Axioms)
Addition inference rules are derived from Armstrong's basic axioms and they make it easier to work with functional dependencies. The derived rules are listed below.
- Union rule
- Decomposition rule
- Pseudotransitivity rule
Union Rule
If \space X \rightarrow Y \space X \rightarrow Z , then \space X \rightarrow YZ
It means two dependents ( Y , Z ) with same determinant (X can be combined into one.
Decomposition Rule
If \space X \rightarrow YZ, \space then \space X \rightarrow Y \space \space and \space X \rightarrow Z \space holds
It means any dependency with multiple attributes on right side can be split into smaller groups. The goal here is to split the FD such that we have only single attribute on the right side. There are three reasons for that:
- Its easy to manage the closure of FD with single attribute.
- Some normal forms such as Boyce-Codd normal form need FDs in single attribute form.
- Its very easy to detect redundent and trivial FDs and you can do it manually.
Pseudotransitivity Rule
If \space X \rightarrow Y \space and \space WY \rightarrow Z, \space then \space WX \rightarrow Z \space holds
The usual transitivity is X \rightarrow Y and Y \rightarrow Z, then X \rightarrow is true.
In pseudotransitivity, WX \rightarrow Z holds because WY together determines the attribute set Z (WY \rightarrow Z).
We can generate large FDs from the basic Armstrong's axs and the derived rules from the basic axioms. We need to reduce the closure of FDs, to a smaller size through closure of attributes.
Closure of Attributes (Z^+)
The closure of FDs (F^+)) for a given F, is huge because it runs Armstrong's axioms repeatedly until no more FDs could be generated. We don't need all the FDs in F^+, instead a subset of FDs of F^+ which implies all FDs of F^+ is enough, with needing us to compute the F^+.
Formal Definition of Closure of Attributes
A relation schema R has
- a set of functional dependencies, F of R.
- a set of attributes,Z of R, for which we want to find a closure.
The closure of a set of attributes Z of R, is Z^+. The Z^+ is set of attributes that are functionally determined by Z under F.
How To Find Closure of a Set of Attributes, Z^+ under F
The steps to find closure of a set of attributes, Z^+ is given below.
Step 1: Initialize the Z^+
In the first step, we initialize the by assigning attributes of [katex]Z.
Z^+ = Z
Step 2: Examine all functional dependencies X \rightarrow Y in F iteratively
The step 2 is a loop and it goes through each FD in F.
Step 3: Test if X is a subset of Z^+
As we iterate through each FD in F, we will test whether, right side of the FD is a subset of Z^+.
X \subseteq Z^+
If the condition is true, and X is a subset of Z^+, then add all attributes of Y to Z^+.
Z^+ = Z^+\cup \space Y
Step 5: Repeat Step 3 and Step 4 process for all FDs in F
Continue this to all the FDs in the F, until you cannot add anymore attributes.
Step 6: Display the resultant Z^+
The final Z^+ contains all the attributes functionally determined by Z under F.

Example :
Find the closure of attributes of F = { A \rightarrow B, B \rightarrow C, C \rightarrow D}.
Solution:
Let F = {A \rightarrow B, B \rightarrow C , C \rightarrow D} and Z = {A}
Note that the choice of Z , a set of attribute could be anything. As a database designer, you want to check for a super key or/and find minimum cover (a small set of FDs that implies the same thing as F+). You may like to test different set of Z
Step 1:
Z^+ = Z = {A}Step 2:
We iterate through all FDs and check for condition, Y \subseteq Z^+.
Check A \rightarrow B, since A \subseteq Z^+, add B.
Z^+ = Z^+ \cup B \\
Z^+ = \{A, B\}Check B \rightarrow C, since B \subseteq Z^+, add C.
Z^+ = Z^+ \cup C \\
Z^+ = \{A , B, C\}Check C \rightarrow D, since C \subseteq Z^+, add D.
Z^+ = Z^+ \cup D\\
Z^+ = \{A , B, C, D\}We followed Step 3, 4 and 5 together above to get the final Z^+.
Step 6: Display final results.
Z^+ = \{A, B, C, D\}Equivalence of Functional Dependencies
We know that closure get huge and we don’t need all the FDs, if there is a small set of FDs which implies the same things as F^+, it is called equivalent set of functional dependendencies.
Let there be two sets of functional dependencies, F and H, are said to be , if they implies exactly the same functional dependencies, which means:
F^+ = H^+
How this Helps in Database Design
The equivalence helps in database design in number of ways.
- Simplification – replacing a large set of dependencies with a smaller set increases the efficiency of the database. The smaller set is the “canonical cover” for the larger set. From definition, if a database applies F^+, the equivalent set His also applied. In other words, H is cover for F^+.
- Normaliztion – the use of smaller set is desired in some normal forms such as BCNF or 3NF.
- No Loss of Data – reducing the size of set of FD, , rewriting, deleting FDs, ensure that there is no loss of constraints ,and therefore, no loss of data.
Example:
Let F and H be two sets of functional dependencies where:
F = \{A \rightarrow B, B \rightarrow C \} \\\\
H = \{A \rightarrow B, A \rightarrow C \}Closure of set of attributes of F
Z^+ = \{A\}\\
Check \space A \rightarrow B, A \subseteq Z^+ \\ Add \space B \\ Z^+ = Z^+ \cup B \\
Check \space B \rightarrow C, B \subseteq Z^+ \\ Add \space C \\ Z^+ = Z^+ \cup C\\
Z^+ = \{A, B, C\}Closure of set of attributes of H
Z^+ = \{A\}\\
Check \space A \rightarrow B, A \subseteq Z^+ \\ Add \space B \\ Z^+ = Z^+ \cup B \\
Check \space A \rightarrow C, B \subseteq Z^+ \\ Add \space C \\ Z^+ = Z^+ \cup C\\
Z^+ = \{A, B, C\}The closure of attributes for both F and H are same, they are equivalent set of FDs.
Minimum(Canonical) Cover of a Set of Functional Dependencies (F)
The canonical cover (also known as minimum cover) for a set of functional dependencies F is the simplified equivalent set of functional dependencies without redundancy and implies the same rules as F.
A set of FDs, F_c is canonical cover for another set of FDs, F, if:
F_c \equiv F
and F_c satisfy 3 conditions of minimality.
- Right-hand side of FDs are reduced to single attribute.
- Left-hand side of FDs should not have extroneous attributes.
- No FD can be removed without changing the closure of F, that is, evey FD in F is unique.
We shall explore these conditions in more detail.
1. Right-Hand Side side of FDs are reduced to single attribute.
Given a set of FD, F, each dependency should be in the form, X \rightarrow Y, that is, the right-hand side of FD contains only a single attribute.
If the FD is of the form:
X \rightarrow A_1,A_2, A_3, ..., A_n
Then we should split the FD into following:
F = \{X \rightarrow A_1, X \rightarrow A_2, ..., X \rightarrow A_n\}2. Left-hand side of FDs, should not have extraneous attributes
Each FD in the set of FDs, F has no extraneous attributes on its left-hand side. All attributes on the left-hand side are essential for dependency to hold and cannot be removed them, unless they are redundent.
If the FD X \rightarrow Y has following form with Z = \{A, B\}.
F = \{AB \rightarrow C, B \rightarrow C\}Step 1: Form a new set of attribute Z, where
Z = (X - \{A\}) = \{B\}It means find a new set of attributes without \{A\} without changing anything in the set of FDs, F.
Step 2: Find closure of new Z
Z^+ = \{B, C\}Step 3: Check the condition for extraneous attribute
Y \subseteq Z^+, \space where \space Z = (X - \{A\})We can see that C \in Y and C \in Z^+, therefore, A is extraneous attribute.
If all attributes in Y can be functionally determined from Z (where Z=X−\{A\}), that is, if Y \subseteq Z^+, then attribute A is extraneous in the left-hand side of the FD X \to Y.
3. No redundant Dependencies
There must not be any redundant FDs in the equivalent set of FDs, F_c, since F_c \equiv F, if unique FD is removed than it
will change the closure and equivalence not longer holds.
If a FD f \in F_c:
Step 1: Find a new set of FD,
F_r = (F_c - \{f\})Step 2: Find closure of F_r.
{F_r}^+ = (F_c - \{f\})^+Step 3: Check if f can be derived from (F_c - \{f\})^+
(F_c - \{f\})^+ \nsupseteq fStep 4: If the condition is true and you cannot derive f from (F_c - \{f\}) then fis not redundant. If the condition is false , then FD, f is redundant.
Example
Let F = \{A \to B, B \to C, A \to C\} be set of dependencies and f = A \to C be the FD for redundancy test.
Step 1: Find the new set of dependencies F_r without f.
(F - \{f\} ) = \{A \to B, B \to C\}Step 2: Find closure of the new set of FDs, (F - \{f\}).
(F - \{f\})^+ = \{A \to B, B \to C, A \to C\}Step 3: Check if F is equivalent to the new set of functional dependencies, (F -\{f\}).
F^+ \equiv (F - \{f\})^+Clearly, closure of F is equivalent to closure of new set of functional dependency, (F - \{f\}), which implies that the functional dependency A \to C is redundant. We can discard it safely.
Procedure to Find the Canonical Cover of a Set of Functional Dependencies (F
A canonical cover must satisfy the three conditions mentioned below.
- The RHS of each functional dependencies in F must be a single attribute.X \to A where A is single attribute.
- F must not contain extraneous attributes. If F \to Y is a functional dependency , then X cannot have extraneous attributes.
- No redundant FDs allowed which means F^+ \equiv (F - \{f\})*+.
Example 1
Find the canonical cover for the following set of functional dependencies, F.
F = \{A \to BC , B \to C\}Solution:
For the given F = \{A \to BC, B \to C\}
Step 1: Split the RHS of each functional dependecy into single attributes.
F = \{A \to BC, B \to C\} \space becomes \space \\F = \{A \to B, A \to C, B \to C\} \space after \space splittingStep 2: Check if LHS has extraneous attributes
There is no extraneous attributes in F.
Step 3: Check if there is redundant functional dependencies in F.
Let us remove A \to C and create a new set of functional dependency F_c.
F_c = (F - \{f\}) =\{A \to B, B \to C\}Step 4: Find closure of F_c
{F_c}^+ = \{A \to B, B \to C, A \to C\}The F_c and F are equivalent A \to C is redundant.
The canonical cover for the set of functional dependencies F is:
F_c = \{A \to B, B \to C\}Summary of Functional Dependency in DBMS
A Functional Dependency (FD) defines a relationship between attributes, written as X \to Y, meaning X[/katex uniquely determines [katex]Y.
- FDs are the foundation of normalization and help identify redundant data, anomalies, and keys.
- There are two main types:
- Trivial FD: Y \subseteq
- Non-trivial FD: Y \not\subseteq X
- The closure of a set of FDs (F^+) contains all FDs implied by F.
- The attribute closure (X^+) lists all attributes functionally determined by X.
- Armstrong’s Axioms (Reflexivity, Augmentation, and Transitivity) form the logical basis for all FD derivations.
- A canonical cover (or minimal cover) is a simplified equivalent of a set of FDs that:
- Has only one attribute on the right-hand side.
- Has no extraneous attributes on the left-hand side.
- Has no redundant dependencies.
- FDs are essential for determining candidate keys, normal forms, and lossless decomposition during database design.
- In practice, understanding and simplifying FDs ensures that database schemas are consistent, minimal, and free of anomalies.