Table of Contents
Designing a database structure without proper planning would cause duplicate data and problem updating the database. This will result in an inconsistent database. The process of normalization is to make an efficient database design that allow faster and efficient access while maintaining the accuracy.
What is Normalization?
Normalization is a database design technique that cuts down data redundancy and eliminates undesirable characteristics like Insertion, Update, and Deletion Anomalies. Normalization rules divide larger tables into smaller tables and attach them using relationships. Normalization in SQL’s objective is to get rid of redundant (repetitive) data and ensure data is stored logically.
Normalization is the process of reducing redundancy from a relation or set of relations. Redundancy in relation may cause insertion, deletion, and update irregularities. So, it helps to minimize the extra in relations Normal forms are used to eliminate or cut down excess in database tables.
Normalization is used for mainly two purposes,
• Eliminating redundant(useless) data.
• Verifying data dependencies make sense that is data is logically stored.
What is a KEY in SQL?
A KEY in SQL is a value used to recognize records in a table uniquely. An SQL KEY is a single column or addition of multiple columns used to uniquely spot rows or tuples in the table. SQL Key is used to point out duplicate information, and it also helps establish a relationship between multiple tables in the database.
Note: Columns in a table that are NOT used to identify a record distinctive are called non-key columns.
What is a Primary Key?
A Primary Key is the minimal set of attributes of a table that has the task of uniquely identifying the rows, or we can say the tuples of the given particular table.
A primary key of a relation is one of the possible candidate keys which the database designer thinks it’s primary. It may be selected for favorable, performance, and many other reasons. The choice of the possible primary key from the candidate keys depends upon the following conditions. Rules for defining the Primary key are:-
- Two rows can’t have the same primary key value
- It must be for every row to have a primary key value.
- The primary key field cannot be false.
- The value in a primary key column can never be modified or updated if any foreign key refers to that primary key.
Why do we need Primary Key?
Suppose for any identification we need a different feature that makes it special(different) from others. Everyone has a unique specialty that makes us judge and verifies them based on that quality one has in them.
Similarly, for differentiating a table from others and for identifying them we need a special key control that can be used to validate the records of that table and maintain uniqueness, consistency, and completeness.
Also, for joining any two tables in the relative database systems, a Primary key and another table’s Primary key are known as a Foreign Key, which plays an important role.
So, we can use this Primary Key while creating a table or change it in the database. If a Primary Key is already present in the table, then the server or system will not allow inserting a row with the same key. It helps to improve the security of database records.
What is the Foreign Key?
FOREIGN KEY is a column that creates a relationship between two tables. The purpose of Foreign keys is to maintain data constancy and allow navigation between two different instances of an organization. It acts as a double verification between two tables as it references the primary key of another table.
Foreign Key references the primary key of another Table! It helps connect your Tables
• A foreign key can have a different name from its primary key
• It ensures rows in one table have relative rows in another, Unlike the Primary key, they do not have to be special from others. Most often they don’t have.
• Foreign keys can be invalid even though primary keys cannot be empty.
Example of Foreign Key
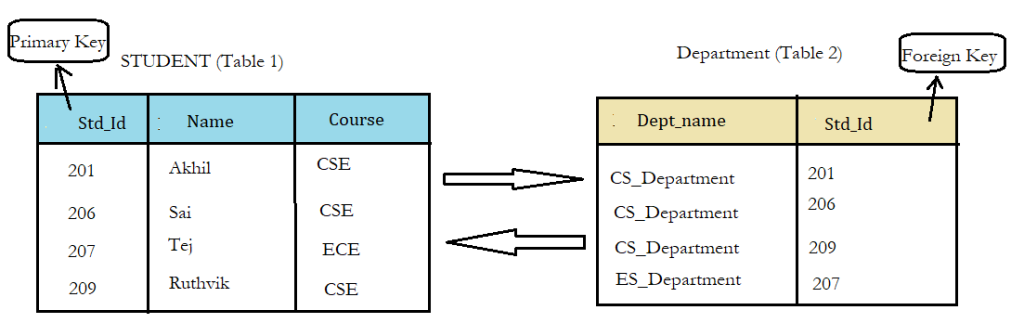
Consider two tables Student and Department having their particular attributes as shown in the below table structure: –
In the tables, one attribute, you can see, is common, that is Std_Id, but it has different key constraints for both tables. In the Student table, the field Std_Id is a primary key because it is uniquely identifying all other fields of the Student table.
On the other hand, Std_Id is a foreign key attribute for the Department table because it is acting as a primary key attribute for the Student table. It means that both the Student and Department table are linked with one another because of the Std_Id attribute.
Difference Between Primary key & Foreign key
Following are the main difference between the primary key and foreign key:
Primary Key
- Helps you to uniquely identify a record in the table.
- Primary Key never accepts clear values.
- The primary key is a clustered index and data in the DBMS table are physically organized in the sequence of the clustered index.
- You can have the single Primary key in a table.
Foreign Key
- It is a field in the table that is the primary key of another table.
- A foreign key may accept multiple empty values.
- A foreign key cannot automatically create an index, grouped or non-grouped. However, you can manually create an index on the foreign key.
- You can have multiple foreign keys on a table.
What is the Composite key?
COMPOSITE KEY is a combination of two or more columns that uniquely identify rows in a table. The combination of columns ensures uniqueness, though individually uniqueness is not guaranteed. Hence, they are combined to uniquely identify records in a table.
The difference between the compound and the composite key is that any part of the compound key can be a foreign key, but the composite key may or maybe not be a part of the foreign key.
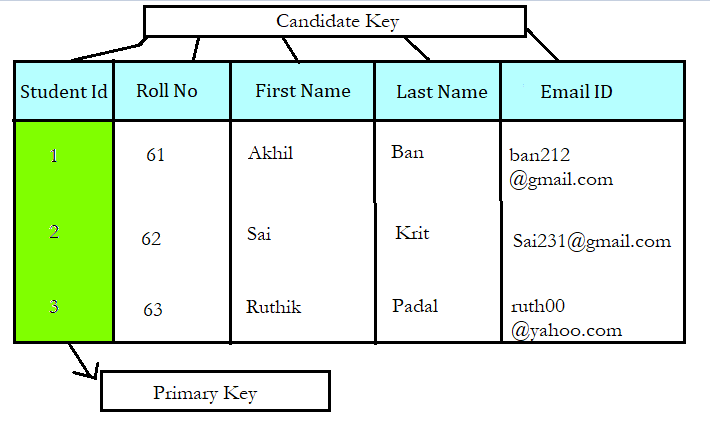
What is a Candidate’s Key?
CANDIDATE KEY in SQL is a set of attributes that uniquely identify substrings in a table. Candidate Key is a super key with no repeated attributes. The Primary key should be selected from the candidate keys. Every table must have at least a single candidate key. A table can have multiple candidate keys but only a single primary key.
Advantages of Normalization:
- Normalization helps to cut down the data redundancy.
- Greater overall database organization.
- Data consistency within the database.
- Much more workable database design.
- Applies the concept of relational integrity.
Disadvantages of Normalization:
- You cannot start building the database before knowing what the user needs.
- The performance degrades when normalizing the relations to higher normal forms, that is 4NF, 5NF.
- It is very time-consuming and difficult to normalize relations of a peak degree.
- Careless decomposition may lead to a bad database design, leading to serious problems.
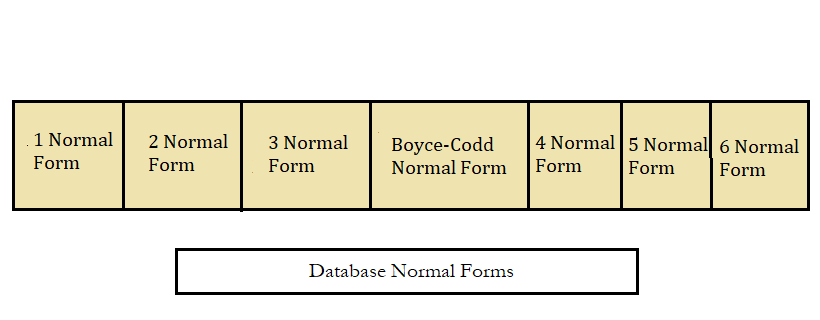
Database Normal Forms
Here is a list of Normal Forms in SQL:
- 1NF (First Normal Form)
- 2NF (Second Normal Form)
- 3NF (Third Normal Form)
- BCNF (Boyce-Codd Normal Form)
- 4NF (Fourth Normal Form)
- 5NF (Fifth Normal Form)
- 6NF (Sixth Normal Form)
1st Normal Form (1NF)
It is Step 1 in the Normalization procedure and is considered the most basic requirement for getting started with the data tables in the database. If a table in a database is not capable of forming a 1NF, then the database design is considered to be poor. 1NF proposes a scalable table design that can be extended easily to make the data retrieval process much simpler.
For a table in its 1NF,
- Data Atomicity is maintained. The data present in each attribute of a table cannot contain more than one value.
- For each set of related data, a table is created and the data set value in each is identified by a primary key applicable to the data set.
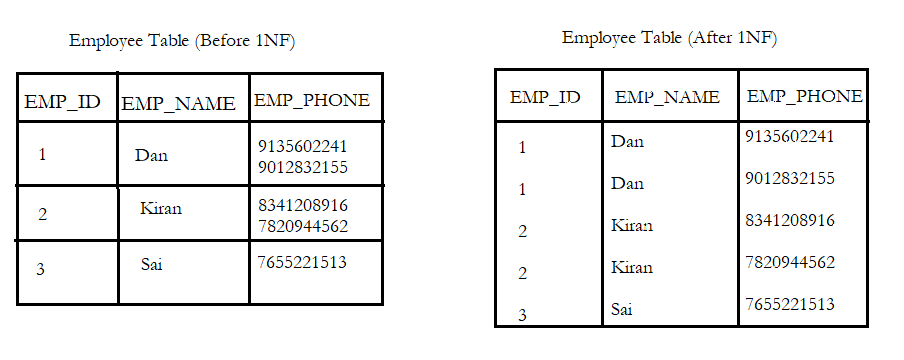
The multiple values from EMP_PHONE made atomic based on the EMP_ID to satisfy the 1NF rules.
2nd Normal Form (2NF)
The basic prerequisite for 2NF is:
- The table should be in its 1NF,
- The table should not have any partial dependencies
Partial Dependency: It is a type of functional dependency that occurs when non-prime attributes are partially dependent on part of Candidate keys.
Example:
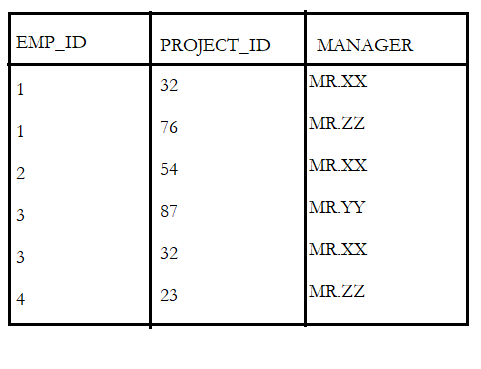
- If manager details are to be fetched for an employee, multiple results are returned when searched with EMP_ID, to fetch one result, EMP_ID and PROJECT_ID together are considered as the Candidate Keys.
- Here the manager depends on PROJECT_ID and not on EMP_ID, this creates a partial dependency.
- There are multiple ways to get rid of this partial dependency and cut off the table to its 2nd normal form, one similar method is adding the Manager information to the project table as shown below.
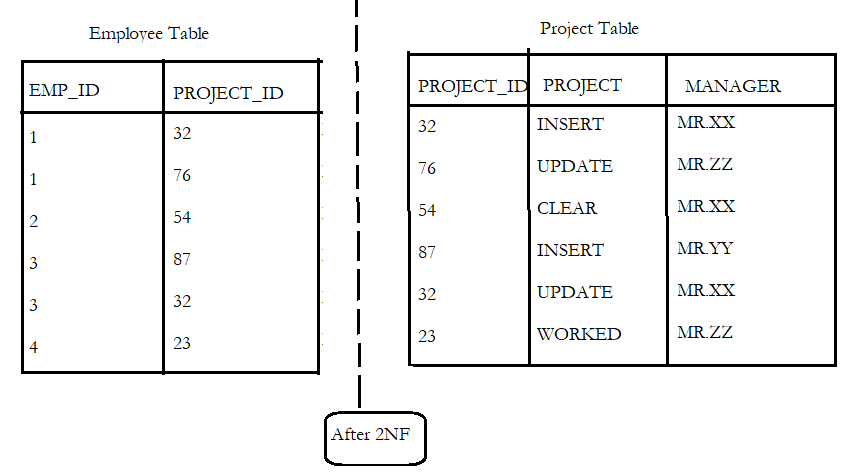
3rd Normal Form (3NF)
3NF ensures referential integrity, cut down the duplication of data, cuts down data anomalies, and makes the data model more informative. The basic prerequisite for 3NF is,
1. The table should be in its 2NF, and
2. The table should not have any transitive dependencies
Transitive dependency: It occurs due to a resulting relationship within the attributes when a non-prime attribute has a functional dependency on a prime attribute.
Example:
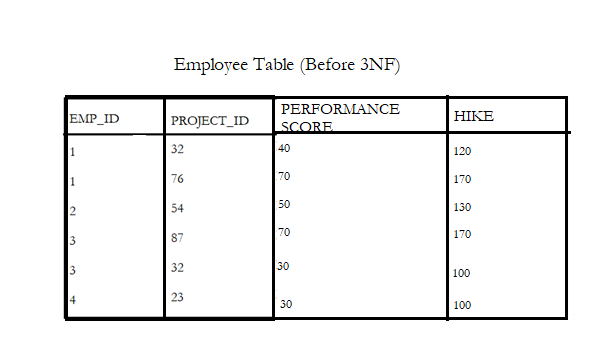
- In Table the PERFORMANCE_SCORE depends on both the employee and the project that he is associated with, but in the last column, HIKE depends on PERFORMANCE_SCORE.
- The hike changes with performance and here the attribute performance score is not a primary key. This forms a transitive dependency
- To get rid of the transitive dependency created, and to satisfy the 3NF, the table is broken as illustrated below:-
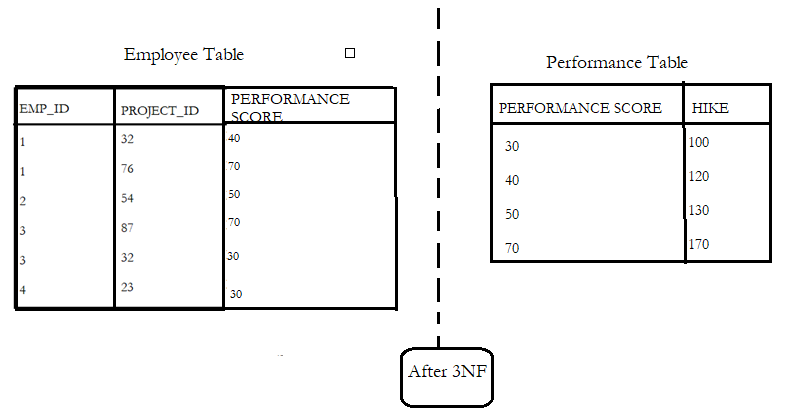
Boyce-Codd Normal Form BCNF
BCNF deals with the anomalies that 3 NF fails to address. For a table to be in BCNF, it should satisfy two conditions:
1. The table should be in its 3 NF form
2. For any dependency, A à B, A should be a super key i.e. A cannot be a non-prime attribute when B is a prime attribute.
Example:
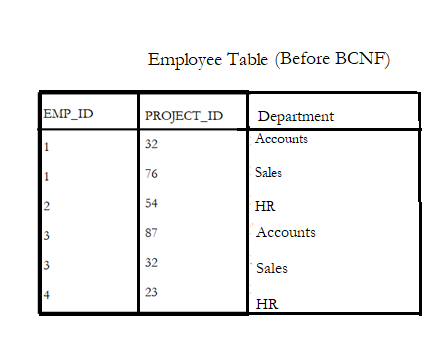
The EMP_ID and PROJECT_ID together can fetch the Department details associated with the employee. i.e.
- EMP_ID + PROJECT_ID → DEPARTMENT
- (Candidate keys)
- DEPARTMENT which is not a super key is dependent only on PROJECT_ID but not dependent on EMP_ID
- Department → Project_ID
- (Non-prime attribute) (prime attribute)
To make this table satisfy BCNF, we need to break the table as shown below:-
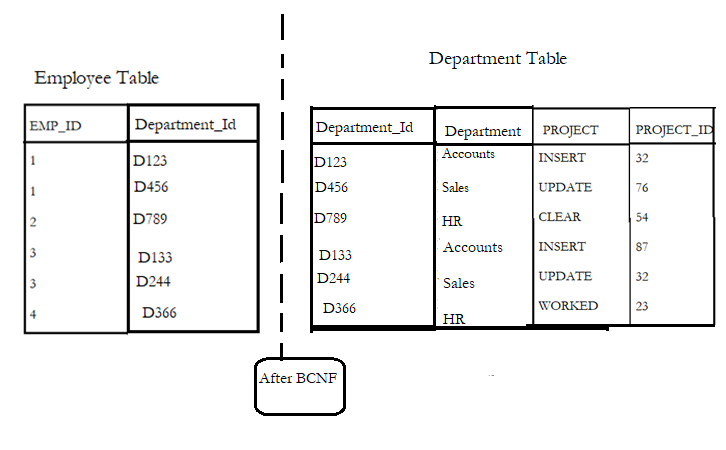
Here the department table is created such that each department id is unique to the department and project-related to it.
It is very important to ensure that the data stored in the database is meaningful and the chances of anomalies are minimal to zero. Normalization helps in reducing data redundancy and helps make the data more meaningful.
Normalization follows the principle of ‘Divide and Rule’ wherein the tables are divided until a point where the data present in them makes actual sense. It is also important to note that normalization does not fully get rid of the data redundancy rather its goal is to minimize the data redundancy and the problems associated with it.
Summary
So, you have learnt the normalization process for designing an efficient database. In most of the cases, the 3rd normal form is enough to create an excellent structure and we never goes to a higher normal form.
It is because of the normal forms a proper functional dependency is maintained.