In this article you will learn about storage structure and disk scheduling algorithms. You analyses the advantages and disadvantages of different disk scheduling algorithms. Learn to measure the performance of disk such as seek time.
A problem is given for each algorithm, you can also try to solve them if you are already familiar with the concepts.

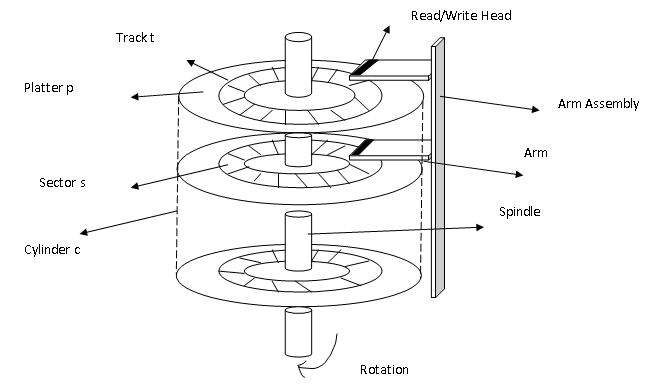
A surface of the circular platter is divided into tracks and tracks are subdivided into sectors. A storage capacity of the disk is measured in GB. The disk rotates 60 to 200 times per second. The transfer rate is the rate at which data transfer between disk and computer.
Positioning time or random-access time is the time necessary to position the arm to the desired cylinder called the seek time.Time taken for the sector to rotate to the disk head is rotational latencies. Both seek time and rotational latencies are of several milliseconds.
The distance between the disk head and the platter is very less (microns) and the head sometimes comes in contact with the disk surface damaging it. This accident is called the head crash.
Removable disks
They work like the normal Hard disks and their capacity is measured in GBs. Some disks are attached to the computer using Buses and their type as follows.
- EIDE – Enhanced Integrated Drive Electronics
- ATA – Advanced Technology Attachments
- SATA – Serial ATA
- USB – Universal Serial Bus
- FC – Fiber Channel
- SCSI – Small Computer-System Interface
Data transfer is carried out by a processor called the controller.
Host controller – computer end of the bus
Device Controller – built into the each disk drive.
Disk Structure
Modern disk drives are accessed as a logical block which is the smallest unit of transfer. A block may be of 512 bytes, but some disks are low-level formatted and have 1024 bytes block size.
One dimensional array of a logical block is mapped to sectors, starting from sector 0 which is the first sector in the first track of outermost cylinder. The mapping proceeds to other cylinders in this way from cylinder 0 to N-1.
What is the use of such mapping?
Using the block address we can find the cylinder and track number and sector number on the track. Such a translation is difficult because some disk may have defects and second, number of sectors per track is not a constant.
A track in an outer zone has more sectors than inner tracks. It has 40 % more sectors. To read and write at a constant speed, either keep the head constant and increase or decrease the rotation speed of the disk.
Otherwise, keep the rotational speed same and change the density of bits as the head moves from inner track to outer most track ( constant angular velocity).
Disk Attachment
- Host –Attached Storage
- Network-Attached Storage
Host Attached Storage
It is accessed through local I/O ports of a computer. Desktop PC uses I/O bus architecture called IDE or ATA, SATA etc.The high-end server uses SCSI or FC (Fiber channel). SCSI is a bus architecture and SCSI protocol supports 16 devices per bus.
SCSI Initiator – The host which has a controller card.
SCSI target – SCSI disk drives are the targets.
Physically it is a ribbon cable with a large number of conductors. FC is high-speed serial architecture and uses fiber cable or a 4 -conductor copper cable. It is mostly used in SAN storage.
Network Attached Storage (NAS)
It is a special purpose storage system that is accessed remotely over a data network. Clients access NAS using RPC interface and RPC is carried via TCP or UDP over IP network such as a LAN. iSCSI is another NAS that carry SCSI protocol over an IP network.
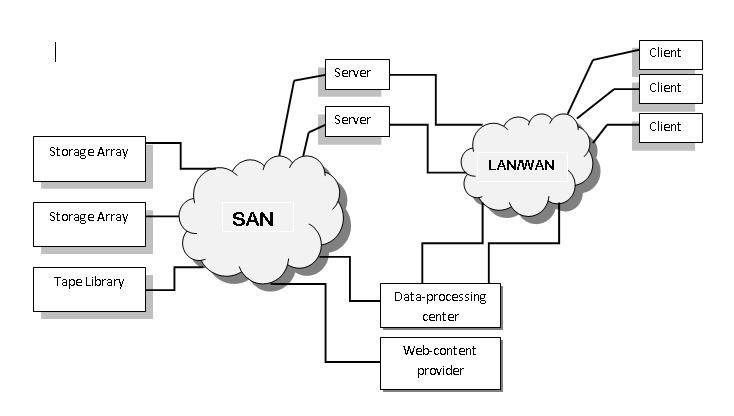
Storage-Area-Network (SAN)
SAN is a private network using storage protocols rather than networking protocols. It connects servers and storage together. Multiple hosts and Storage arrays can connect to same SAN and it can be dynamically allocated to hosts. SAN has more ports and less expensive ports than the storage array ports and SAN switch control the access to storage by hosts.

Disk Scheduling
The disk access time has two components – seek time and rotational latency.
Disk Bandwidth – It is the total number of bytes transferred divided by the total time between the first request for service and last transfer.
By scheduling the disk access we can reduce the time a process has to wait for disk operation to complete. In multi-programming, the number of a process request for disk device access and if the device is already processing a request the process has to wait in the device queue with other pending requests.
FIRST COME, FIRST SERVE
It is not an efficient algorithm but it is fair in scheduling the disk access. For example, we are given a list of request for disk I/O to blocks on a cylinder.
98, 183, 37, 122, 14, 124, 65, 67If the starting point is 53 then the access would be like below

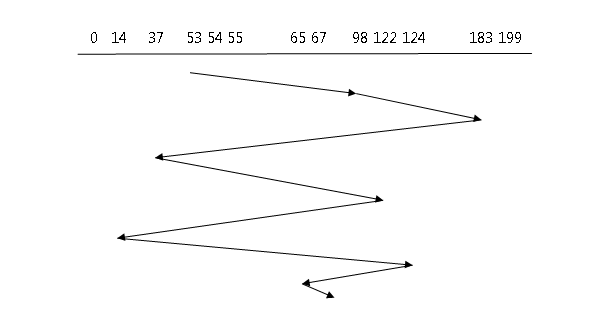
The big jump from 183 to 37 could be avoided if somehow 14, 37 and 122, 124 are served together. This indicates the problem with the FCFS algorithm which is larger head movement.
SSTF SCHEDULING
The main idea of the Shortest-Seek-Time-First algorithm is to service all the requests close to the current position of the head before moving far away to service other requests.
Example:
Considering our previous sequence of disk blocks access.
Queue = 98, 183, 37, 122, 14, 124, 65, 67
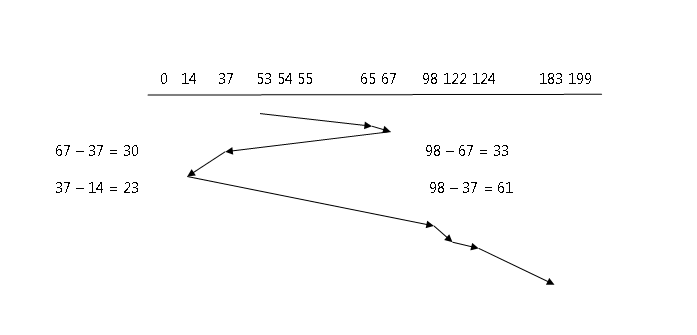
There is a substantial improvement compared to FCFS algorithm. The total head movement is as follows.
65 – 53 = 12 37 – 14 = 23 124 – 122 = 2
67 – 65 = 2 98 – 14 = 84 183 – 124 = 59
67 – 37 = 30 122 – 98 = 24
Total Head Movement = 236 cylinders.But suppose 14 and 183 are a queue and a request near 14 came, it will be served and next one is also close to 14 came, it will be served first and this will lead to starvation of 183 in the queue. SSTF is an improvement but not the optimal algorithm.
SCAN SCHEDULING
In this algorithm, the disk arm works like an elevator starting at one end servicing all the way up to the other end and then start from the other end in reverse order.To use the SCAN algorithm, we need to know two information.
- Direction of Scan
- Starting point
Let’s consider our example and suppose the disk start at 53 and move in the direction of 0.

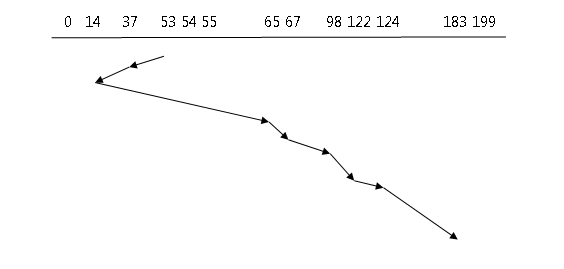
Total Head Movement
53 – 37 = 16 67 – 65 = 2 124 – 122 = 2
37 – 14 = 23 98 – 67 = 31 183 – 124 = 59
65 – 14 = 51 122 – 98 = 24
Total head movement = 158The SCAN move in one direction and service all the request immediately, but while returning in reverse direction it does not serve any request since they have been serviced recently. More of the request is at the opposite end, we will see an algorithm that wants to go the other end directly.
C-SCAN ALGORITHM
In this algorithm, the head from one end to the other servicing request along the way, however, it does not do a reverse trip and go to the beginning directly as if it is a circular queue.

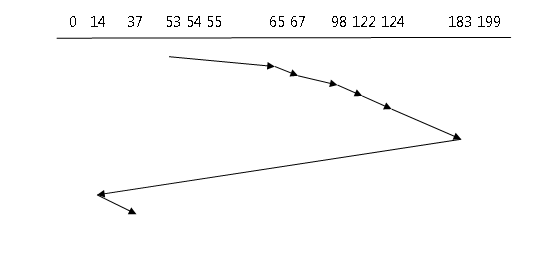
Total Head Movement
183 -124 = 59 98 – 67 = 31 183 – 14 = Look for Request
124 – 122 = 2 67 – 65 = 2 37 – 14 = 23
122 – 98 = 24 65 – 53 = 12
Total Head Movement = 153LOOK SCHEDULING AND C-LOOK SCHEDULING
SCAN and C-SCAN not implemented as they described earlier, but they move to one direction and reverse its direction of movement rather than directly going to the beginning.
References
- Abraham Silberschatz, Peter B. Galvin, Greg Gagne, A Silberschatz. 2012. Operating System Concepts, 9th Edition. Wiley.
- Technology, Illinois Institute of Technology. n.d. Disk Scheduling Algorithms. Accessed 7 24th, 2016. cs.iit.edu.