Previously, you learned about the concurrency mechanism in database. You know that the concurrency is maintained in a serialized manner, giving the impression that there is indeed some concurrency. The locking technique has to do a lot with this achievement of efficient access to database.
What is a Lock?
A lock is a variable associated with a data item that describes the status of the item concerning possible operations that can be applied to it. Accordingly, there is one lock for each data item in the database. Locks are used as a means of synchronizing the access by concurrent transactions to the database item.
Locking protocols are used in database management systems as a means of concurrency control. Many transactions may request a lock on a data item simultaneously. So, we require a mechanism to manage the locking requests made by transactions. Such a process is called Lock Manager.
It relies on the process of message passing where transactions and lock managers exchange messages to handle the locking and unlocking of data items.
Concurrency control protocols can be broadly divided into two categories −
- Lock based protocols
- Timestamp based protocol
Lock-based Protocols
Database systems equipped with lock-based protocols use a method by which any transaction cannot read or write data until it acquires an appropriate lock on it. Locks are of two varieties:
- Binary Locks − A lock on a data item can be in two states; it is either locked or unlocked.
- Shared/exclusive − This type of locking method differentiates the locks based on their uses. If a lock is obtained on a data item to perform a write operation, it is an exclusive lock.
Allowing more than one transaction to write on the same data item would lead the database into an incompatible state. Read locks are divided because no data value is being changed.
Types of Locks
Several types of locks are used in concurrency control. To implement locking concepts gradually, we need to talk about binary locks, which are simple but restrictive and so are not used in practice.
After it shared/exclusive locks, which provide more general locking capabilities and are used in practical database locking schemes.
What are Binary Locks?
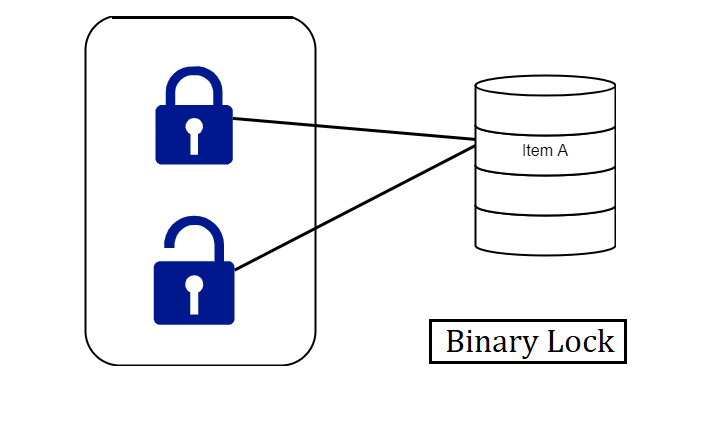
A binary lock can have two states or values locked and unlocked.
A distinct lock is related to each database item A. If the value of the lock on A is 1, item A cannot gain access by a database operation that requests the item.
If the lock value on A is 0 then the item can be accessed when requested. We refer to the current value of the lock associated with item A as LOCK (A).
There are two operations, lock item and unlock item are used with binary locking A transaction requests access to an item A by first issuing a locked item (A) operation. If LOCK (A) = 1, the transaction is forced to wait. If LOCK (A) = 0 it is set to 1 (the transaction locks the item) and the transaction is allowed to access item A.
When the transaction is through using the item, it issues an unlock item (A) operation, which assigns LOCK (A) to 0 (unlocks the item) so that A may be accessed by remaining transactions. Hence binary lock imposes mutual exclusion1 on the data item.

Rules of Binary Locks
Incase the simple binary locking scheme described here is used, every transaction must obey the following rules:
- A transaction must supply the operation lock_item (A) before any read_item (A) or write, item operations are performed in T.
- A transaction T must supply the operation unlock_item (A) after all read_item (A) and write_item (A) operations are completed in T.
- A transaction Twill does not supply a lock _item (A) operation if it already holds the lock on Item A.
- A transaction will not issue an unlock _item (A) operation unless it already holds the lock on item A.
- The lock manager module of the DBMS can implement these rules. Between the Lock_item (A) and unlock_item (A) operations in transaction T, is said to hold the lock on item A.
At most one transaction can hold the lock on a particular item. Thus no two transactions can access the same item together.
Merits of Binary Locks
- They are simple to execute since they are effectively mutually exclusive and establish isolation perfectly.
- Binary Locks request less from the system since the system must only keep a record of the locked items. The system is the lock manager subgroup which is a feature of all DBMSs today.
Disadvantages of Binary Locks
As discussed earlier, the binary locking scheme is too restrictive for database items, because at most one transaction can hold a lock on a given item. So, a binary locking system cannot be used for practical purposes.
One of the methods to ensure isolation of property in the transactions is to require data items to be accessed in a mutually exclusive manner. That means, that while one transaction is accessing a data item, no other transaction can make changes to that data item.
So, the most common method used to implement requirements is to allow a transaction to access a data item only if it is currently holding a lock on that item.
Thus, the lock on the operation is required to ensure the isolation of the transactions.
How Do Shared Locks Function?
- Shared locks survive when two transactions are granted read access.
- One transaction gets the shared lock on data and when the second transaction requests the same data it is also given a shared lock.
- Both transactions are in a read-only mode, updating the data is not allowed until the shared lock is released. There is no difference with the shared lock because nothing is being updated.
- Shared locks last if they need to last; it depends on the level of the transaction that holds the lock.
- Shared locks keep up read integrity. They check whether a record is not in process of being updated during a read-only request.
- Shared locks can also be used to stop any kind of updates of record.
- It is represented by Lock-S which is a read-only lock.
- S-lock is appealed using Lock-S instruction.

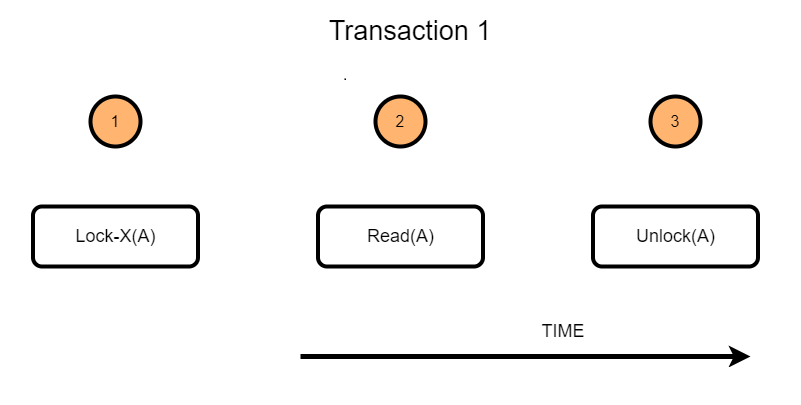
Example:
Consider a case where initially A=100 and two transactions are reading A. If one of the transactions wants to update A, in that case, the other transaction would be reading the wrong value.
However, the Shared lock prevents it from updating until it has finished reading!
Exclusive Locks
We should allow several transactions to access the same item A if they all access A’ for reading purposes only. However, if a transaction is to write an item A, it must have total access to A
. For this purpose, a different type of lock called a multiple-mode lock is used. In this scheme, there are exclusive or read/write locks are used.
Example:
Consider a transaction(T2) that requires updating the data item value A. The following steps take place when lock protocol is applied to this transaction.

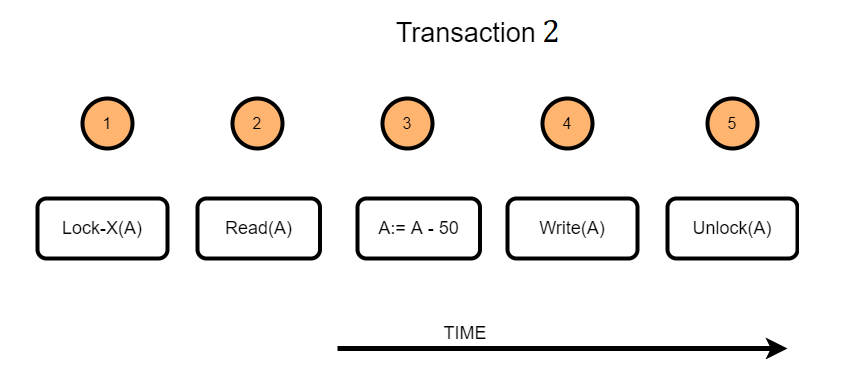
- T2 will acquire an exclusive lock on the data item A
- Read the current value of data item A
- Change the data item as required. In the example illustrated, a value of 50 is subtracted from the data item A
- Write the updated value of the data item
- Once the transaction is finished, the data item will be unlocked.
Differences between Shared Lock and Exclusive Lock
Shared Lock:
- Lock mode is a read-only operation.
- Shared lock can be placed on objects that do not have an exclusive lock already placed on them.
- Prevents others from updating the data.
- Provided when the transaction wants to read an item that does not have an exclusive lock.
- Any number of transactions can hold a shared lock on an item.
- S-lock is appealed using lock-S instruction.
Exclusive lock:
- Lock mode is read as well as write operation.
- Exclusive lock can only be placed on objects that do not have any other kind of lock.
- Prevents others from reading or updating the data.
- Provided when transaction wants to update unlocked item.
- Exclusive lock can be observed by only one transaction.
- X-lock is sought using lock-X instruction.
Locking operations
There are three locking operations called read_lock(A), write_lock(A) and unlock(A) represented as lock-S(A), lock-X(A), unlock(A) (Here, S indicates shared lock, X indicates exclusive lock) can be performed on a data item. appealed
A lock related to an item A, LOCK (A), now has three possible states: “read-locked”, “write-locked,” or “unlocked.” A read-locked item is also called a share-locked item because various transactions are allowed to read the item, whereas a write-locked item is caused exclusive-locked. Hence, a single transaction exclusively holds the lock on the item.
Compatibility of Locks
Suppose that there are A and B two different locking modes. If a transaction T1 requests a lock of mode on item Q on which transaction T2 currently holds a lock of mode B.
If the transaction can be granted the lock, despite the presence of the mode Block, then we say mode A is compatible with mode B. Such a function is shown in one matrix as shown below:
| S | X | |
| S | True | False |
| X | False | False |
The graphs show that if two transactions only read the same data object they do not conflict, but if one transaction writes a data object and another either reads or writes the same data object, then they dispute with each other.
A transaction requests a shared lock on data item Q by executing the lock-S(Q) instruction. Similarly, an exclusive lock is appealed through the lock- X(Q) instruction. A data item Q can be free via the unlock(Q) instruction.
To access a data item, transaction T1 must first lock that item. If the data item is already locked by another transaction in an opposite mode, the concurrency control manager will not allow the lock until all opposed locks held by other transactions have been released. Thus, T1 is made to wait until all opposed locks held by other transactions have been released.
There are four types of lock protocols available are: –
Simplistic Lock Protocol
Simplistic lock-based protocols allow transactions to obtain a lock on every object before a ‘write’ operation is performed. Transactions may unlock the data item after completing the ‘write’ operation.
Pre-claiming Lock Protocol
Pre-claiming protocols estimate their operations and create a list of data items on which they need locks. Before starting execution, the transaction requests the system for all the locks it needs beforehand.
If all the locks are allowed, the transaction executes and releases all the locks when all its operations are over. If all the locks are not allowed, the transaction rolls back and waits until all the locks are granted.

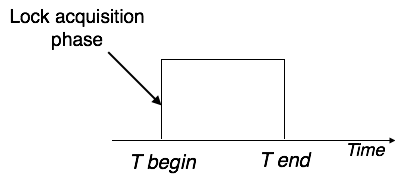
Two Phase Locking 2PL
This locking protocol divides the implementation phase of a transaction into three parts. In the first part, when the transaction starts working, it seeks permission for the locks it requires.
The second part is where the transaction obtains all the locks. As soon as the transaction releases its first lock, the third phase starts. In this phase, the transaction cannot order any new locks; it only releases the acquired locks.

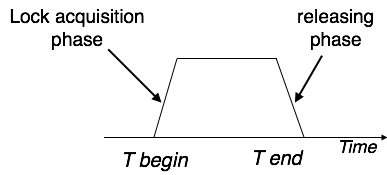
Two-phase locking has two phases, one is increasing, where all the locks are being acquired by the transaction; and the second phase is decreasing, where the locks held by the transaction are being released.
To claim an exclusive (write) lock, a transaction must first obtain a shared (read) lock and then upgrade it to an exclusive lock.
Strict Two-Phase Locking
The first phase of Strict-2PL is the same as 2PL. After obtaining all the locks in the first phase, the transaction continues to execute normally.
But in contrast to 2PL, Strict-2PL does not release a lock after using it. Strict-2PL holds all the locks until the commit point and releases all the locks at a time.
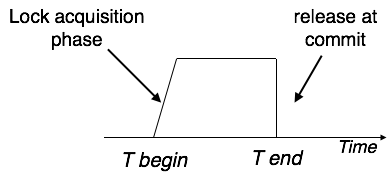
Strict-2PL does not have to cascade termination as 2PL does.
Timestamp-based Protocols
The most used concurrency protocol is the timestamp-based protocol. This protocol uses either system time or a logical counter as a timestamp.
Lock-based protocols manipulate the order between the conflicting pairs among transactions at the time of execution, whereas timestamp-based protocols start working as soon as a transaction is created.
Every transaction has a timestamp related to it, and the ordering is determined by the age of the transaction. A transaction created at 0002 clock time would be older than all other transactions that come after it. For example, any transaction ‘y’ entering the system at 0004 is two seconds younger and the priority would be given to the older one.
In addition, every data item is given the latest read and write-timestamp. This lets the system know when the last ‘read and write’ operation was performed on the data item.
Timestamp Ordering Protocol
The timestamp-ordering protocol checks serializability among transactions in their conflicting read and writes operations. This is the responsibility of the protocol system that the various pair of tasks should be executed according to the timestamp values of the transactions.
Let’s assume there are two transactions T1 and T2. Suppose the transaction T1 has entered the system at 007 times and transaction T2 has entered the system at 009 times. T1 has the higher priority, so it executes first as it is entered the system first.
The priority of the older transaction is higher that’s why it executes first. To decide the timestamp of the transaction, this protocol uses system time or logical counter.
- The timestamp of transaction Ti is represented as TN(Ti).
- Read time-stamp of data-item X is represented by R-timestamp(X).
- Write time-stamp of data-item X is shown by W-timestamp(X).
Timestamp ordering protocol works as follows −
- If a transaction Ti issues a read(X) operation −
- If TN(Ti) < W-timestamp(X)
- Operation rejected.
- If TN(Ti) >= W-timestamp(X)
- Operation executed.
- All data-item timestamps are updated.
- If a transaction Ti issues a write(X) operation −
- If TN(Ti) < R-timestamp(X)
- Operation rejected.
- If TN(Ti) < W-timestamp(X)
- Operation rejected and Ti rolled back.
- Otherwise, the operation is executed.
Concurrency control is important in DBMS for handling the simultaneous execution of transactions among various databases.
Lock Based Protocols being an essential member of the concurrency control technique enforces isolation among the transactions, preserves and maintains the reliability of the database, and resolves the disputes of read-write and write-read operations.
In addition to Lock-based Protocols, concurrency control can also be achieved via methodologies such as Timestamp Protocol, Multiverse concurrency Protocol, and Validation Concurrency Protocols.
Advantages and Disadvantages of Timestamp Ordering protocol:
- Timestamp Ordering protocol ensures serializability since the precedence graph is as follows:

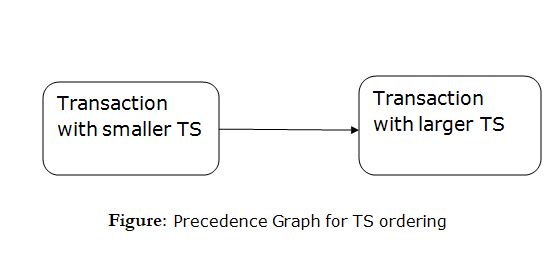
- TS protocol ensures freedom from deadlock which means no transaction ever be in waiting.
- But the schedule may not be modified back and may not even be cascade-free.
Summary
You have learned about different types of lock and their efficiencies, drawbacks in this article. The idea of the efficient lock is to maintain faster access and keep the database consistent. This is done when the transaction is kept atomic and isolated.