Table of Contents
In relational database system, the three-level architecture describes how users view the data. It separates physical storage details from users and applications. It provides data abstraction and data independence.
Why we need this architecture?
The main reasons for three-level architecture is:
Data abstraction
- Users can access data without knowing the physical storage details.
Data Independence
It means changes in one level does not affect the other levels.
- Logical data independence – It means changes in logical schema (tables, relations) does affect the users or applications.
- Physical data independence – changes in the physical storage (disk, indexes) does not affect the logical tables or relations.
Multiple Views of Same Database
- Different users can view database according to their need and privileges’.
For example, an admin can see tables and he can create a new one if needed, but a common user can only see limited view of data provided by the application, they are using.
Security and Consistent Data
The three-level architectures provides security and data consistency.
- The physical data access is restricted.
- Since, DBMS manages everything from one location, the data is consistent, and there are no duplicate records across multiple copies of the database.
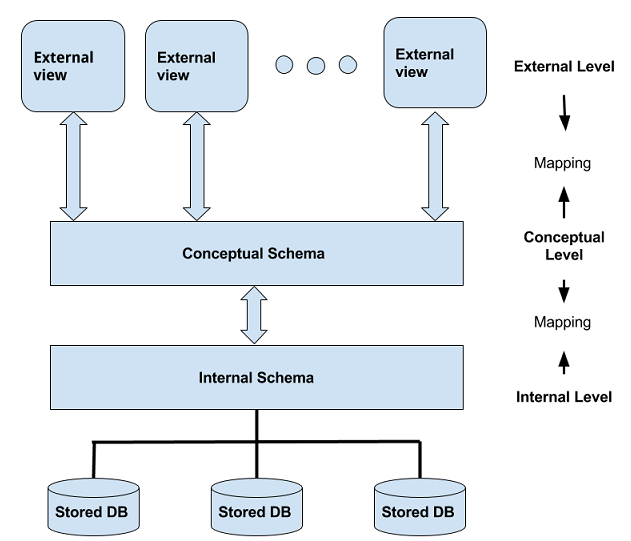
Internal level with internal schema
The internal level is the lowest level of data abstraction. It deals with the physical implementation of the database in a computer system. In other words, it is the physical level.
Storage Structure
It describes how data is organized and stored on a disk storage. There are two main concerns;
- Efficient use of disk space.
- Minimum disk I/O
It is because the disk is slower than the random access memory (RAM) of a computer.
DBMS decides:
- how records are placed in files.
- structure of records, variable length or fixed length.
- how data blocks are arranged.
Only files are part of a file system, where records and blocks are low level details are part of disks. The operating system manage files, file system, blocks and records.
Fast Search and Retrieval of Data
A fast search and retrieval of data is primary concern of physical storage. It is achieved through Indexing. The indexes are added as additional structures at physical level.
The most popular indexing types are:
- B+ trees
- Hash indexes
- Clustered and non-Clustered indexes
The solution is reading data without scanning the whole disk and reducing the disk I/O.
Buffer Management
Buffer is a temporary storage memory, usually, in RAM to hold data, while transferring between to locations or devices. In DBMS, buffer management is an important task.
The buffer pool can hold page table and memory pages.
DBMS do not interact with disk every time. It uses a buffer pool to access data from memory, than accessing disk which is slower process.
The primary concern is to decide which page should remain in memory and which dirty page should sent back to the disk.
Pages are managed with page replacement algorithms such as LRU( Least Recently Used). This directly affect the performance of the database.
Data Security
Data security exists at various levels. At the physical level, the data security is concerned with physical security of infrastructure, servers, etc. This is secured by giving access to only authorized people. Not everyone get the same access permissions. The DBA gets full access to the database.
The main concern for physical security are;
- Data Files
- Disks
- The Backup Disks and Files.
Data files are secured using various encryption techniques. The access control can limit the access to only authorized people to read, write, or modify the data files. Sometimes the files are immediately destroyed if they are no longer required.
Data disk security includes methods like Self-Securing Disks (SSDs), password protection, full disk encryption like FileVault, BItLocker, etc.
Backups are useful incase of loss of data or disks. There two ways to keep backup.
- Local backup
- Offsite back
In either case, backup disks and files need own protection using encryption, access control, and isolating the backup locations.
Even all of these cannot prevent database crash or failures. Next section discuss the integity and recovery of data.
Data Integrity and Recovery
When the database is crashed, our concern is to prevent corruption of physical data and recover the database and any lost data.
This is achieved through transaction logs:
- Write-Ahead-Log (WAL) – Database transactions do not write anything to database because a failure can corrupt database during writing process. Therefore, database transactions follow integrity , atomicity, and durability principles( ACID Properties) and write in the WAL files before they commit the information permanently to the database.
- Checkpoints – A checkpoint in the log files, is a marker that all memory pages are written to the disk and database is consistent. It is used to recover the database to a consistent state.
- Redo/Undo Logs – Redo log store all committed transactions and new values of the data. The Undo logs contains previous versions of data. Database can rollback to previous version if the current transaction fails.
Conceptual Level with Conceptual Schema
In the three-level architecture, conceptual level sits between the external level and the internal level. It describes the logical structure of the complete database regardless of its physical implementation.
Conceptual level is the overall view of the database and it represents all the information going to be represented in the database.
The conceptual level represents;
- What data is stored.
- What is the relationship between data
- Constraints on the data
For example;
Entities – Student , Course, Department
Attributes – StudentID, Name, Grade
Relationship – Students enroll for Courses
This level is usually represented using schemas or models such as Entity-Relationship Models or Relational Model.
What are the main concerns at conceptual level
The main concerns at conceptual level are listed below:
- Logical structure
- Relationship between data
- Data integrity constraints
- Data independence
- Security and Authorization
Logical Structure
The DBMS at conceptual level must clearly define:
- Tables (relations)
- Attributes (columns)
- Keys ( primary key, foreign keys)
The tables with columns are completely different from how physical records are stored. The keys such as primary key and foreign keys ensures that records are not duplicate. The table allows duplicate data if key is not defined.
Example.
Student Table (Student_id, Name, Department_id)
Relationship between data
The table row represents an instance of an entity. Table is entity type , set of all similar entities.
The relationship between data is how entities are connected. These relationships ensure that the database captures real world structures.
For example.
Student enrolls in a Course
Department offers a Course
Data Integrity Constraints
The data in the database must follow rules and precise structure. The correct data is valid, consistent across database, and meaningful according to the constraints.
A consistent data is that which follows all rules, even though duplicate records exist in the database tables.
Common constraints includes:
- Primary key to uniquely identify records.
- Foreign key to maintain relationships.
- Domain constraints to ensure valid values for attributes.
For example:
In Student Table, Student_id cannot be NULL due to constraint NOT NULL on that field. Student_id can be a Primary Key that uniquely identify the Student Table, therefore, NOT NULL make sure that all students have an ID.
Data Independence
The most important job of conceptual level is to hide the physical storage details from the users. If the storage structure change, a disk, or index, it does not affect the conceptual level. The conceptual schema does not change.
This is called logical data independence.
Security and Authorization
At conceptual level, we are dealing with different types of data. The data is modified, read and deleted. In short, there are many database operations on this data.
Conceptual level decides
- Who can access which data?
- User permissions.
For example,
Students can view their Grades, however, only administrator can modify the Grades.
What is the role of a Conceptual Schema ?
The conceptual schema is the blueprint of the database. It acts like a bridge between external level(user views), conceptual level (logical structure), and internal level (physical storage) of the database.
The overall organization of the data is independent of the physical storage.
External or View level
The external level is the top-layer of the three-schema DBMS architecture. It does not show full database, only relevant part of data to a single user or an application. This is called Views.
For example,
There can be a Student view with fields – Student Name and Grade.
There can be one view for Admin with following fields – Student_id, Name, Grade, Fees.
It is same database , and tables structure but different views for different people.
What are the main concerns of External level?
External level interacts with users. It has different concerns than conceptual and internal level.
- Data abstraction
- Security and Access Control
- User-Specific Views
- Data Independence
Data Abstraction
The main goal of external views is to provide necessary data to the users. Users don’t need to see the internal database structures or physical implementation of DBMS.
Hiding the important database details is the first priority of external views.
For example.
A student only need to see the marks obtained, they don’t need to see the table design, or change anything in the database. A view is generated with only student ID, Name and Marks.
This indicates the security and authorization problems which is discussed in the next section.
Security and Access Control
Security and authorization is most important here. Unauthorized users should not get access to information. The admin protects the views with secured passwords. Every user get their own password and only they are authorized to view the data.
All sensitive data is hidden. Users get only authorized information.
User-Specific Views
User-specific view is customized representation of database that contains only the data a particular user (or role) need.
The views are filtered vertically, then only relevant columns of tables are shown.
Similarly, view are also filtered horizontally, where user can see only specific records.
For example.
Students can see only own records.
Manager can see only his department records.
Data Independence
Change in the internal or conceptual level does not affect the external view. The users will never notice any change happening in database. This is called external data independence.
Summary
| Level | Key focus | Describes | Users |
| External | User view | Different views of data for different users. | Common end users |
| Conceptual | Logical Structure | Logical design of database (Table, Relations) | DB Designers, DBA |
| Internal | Physical Storage | Storing data on disk (File, Indexes) | System/DBMS |