Table of Contents
After data cleaning steps in data mining. You need integration of data sources in data mining. It means combining disparate data sources into a single schematic structure.
There are two major type of integration – schema integration and data integration.
Schema integration forms an integrated schematic structure from the disparate data sources.
The data integration is about cleaning and merging data from different sources.
Schema Integration
Consider the following schemata:
Cars (serial No, model, color, stereo, glass-tint,...)
and
Auto(serienNr, modelle, farbe)There are two tables and one in German. With this type of data there are few challenges listed below.
- Naming difference
- Structural difference
- Data type difference
- Missing fields
- Semantic differences
Generic Architecture of Integrator
The generic architecture of an integrator has components such as extractors, mediator, data sources.
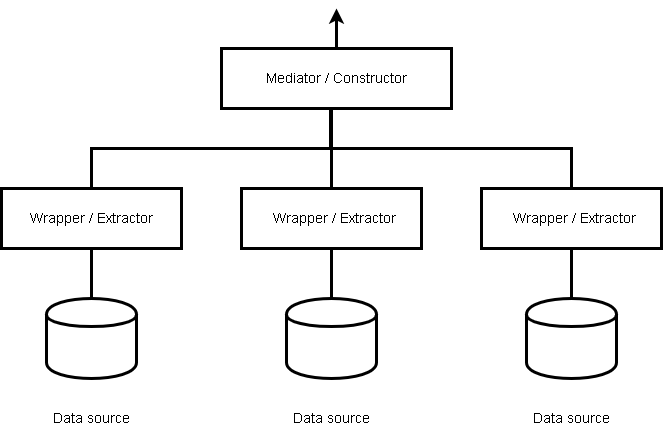
Extractor maps into a standard schema set. The extractors are responsible for transferring data from operational database to data warehouse.
Mediators constructs to overall schema. It is the one responsible for data integration from heterogeneous data sources.
Wrapper / Extractor
Creates a common view across all data sources. It bridges the differences in the naming, type and schema structure. Wrappers do not physically extract data from the data sources, but, send a local query to the target database. The result from this local query is converted into a relational form.
Mediator / Constructor
The mediator constructs an integrated schematic structure and performs data integration and populate the data warehouse.
Tools for Data Cleaning and Integration – dfPower
- It is from Dataflux corporation.
- has a de-duplication engine.
- analyze data based on values and no of occurrences.
- does not support detection of semantic duplicates based on user specified rules
- permits duplicates to be grouped or merged.
Website: http://support.sas.com/software/products/dfdmstudioserver/index.html