Table of Contents
Once the dirty data is identified, we must use appropriate transformation rules on the data. Various transformation algorithms are help to solve different kind of problems with the data such as duplicate elimination, misspellings in the data.
In this article, we will discuss some transformation algorithms.
Hash-Merge for Duplicate Elimination
- Hash tuples based on given column into buckets.
- Tuples with duplicate values are hashed into the same buckets.
- Merge tuples within each bucket separately.
For example:
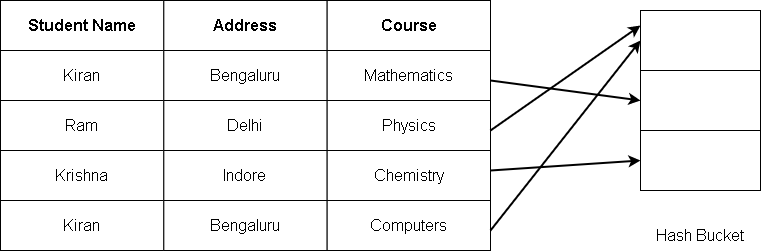
The name and the student address serve as the key. If two records are similar, they are included in the same bucket, thus, eliminating the duplication.
Sorted Neighborhood Technique for Misspelling Integration
The problem with hash key method is that you go over each record to find the duplicate. If the database is extremely large, then it is time consuming.
The sorted neighborhood technique works on the idea that if records are sorted, it is easier to find duplicates because similar tuples will be next to each other.
- Identify a set of attributes as key in the table with N tuples.
- Sort the table based on the key. The key is not unique, but a simple key for sorting data such as ” first 3 letters should be ‘Rav’ “.
- Once the tuples are sorted, you have to create window of W rows over all N tuples.
- Merge the duplicate based on some rules (ex. merge names if all other values like age, address, department, etc matches) within the window.
- If the window size of too small, you may not find some duplicates
- if the window size if too big then also you may miss duplicates.
- Make multiple pass until there are no more merges of records.
For example:
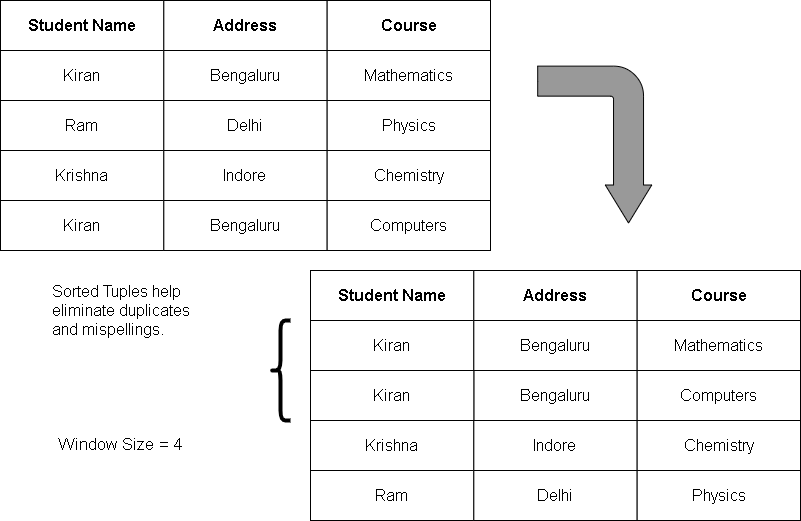
The sorted neighborhood technique ignores misspelled names, omissions in data. The efficiency is solely based on the selection of keys.
Graph-based Transitive Closure to Reduce Number of Passes
This technique answers the question of reducing the number of passes from the sorted neighborhood technique.
- Use sorted neighborhood technique and sort records based on identified keys.
- Create an undirected graph structure where nodes correspond to records and edges corresponds to “is a duplicate of ” relationship.
- Record R1 and R2 need not be compared in any pass if they belong to the same connected component.
Here is an example:
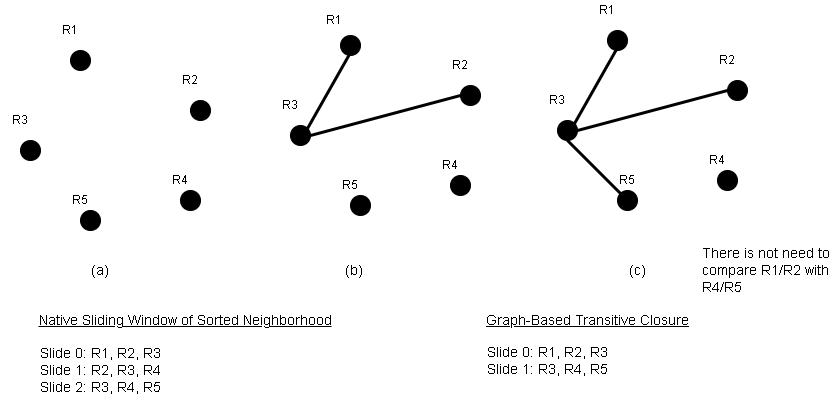
The above diagram clearly shows a reduced number of passes.
In the next article, we will discuss about integrating data into a single schematic structure.