Table of Contents
As we already know that XML is only to hold data and it gives complete freedom to choose any name for elements. XML don’t care about how the document looks or how we are going to use the data.
The only requirement is to follow the rules of the XML document markup language. It is best to choose names for your elements that make sense.
Tags
Elements themselves cannot store information. An element in XML is enclosed within angle brackets (< >) and there are two types of elements – opening element and the closing element. Unlike HTML, where tags are limited, XML asks you to create your own tags.
Consider an example,
<?xml version="1.0"?>
<mail>
<message> Meet me at <emphasis>Delhi</empahsis>School. </message>
</mail>In the above example, we have two elements – <mail> and <message>. The elements are with their respective closing elements, together they are called a tag.
So, when we say tag mail, it means <mail> </mail>. Each of the XML tags contain either another tag or some content. The <mail> tag contains <message> tag and <message> tag contains a “message” text.
The element <emphasis> is inline tag to decorate textual information or provide value add to the content. All tags have the same purpose, that is to label the content meaningfully.
In this way, tags are used to define the label and structure of an XML document.
The XML document is not finished until we apply some style to it. Only then we can say that the document is finished or complete, otherwise, it is just an outlined document using. tags.
The Prolog
First few lines of the XML document are the prolog that describes some information about the document. It is an optional, but if your document contains this, then it must be positioned before the root element.
The contents of prolog are:
- Document type declaration.
- Links to document type definition (DTD).
- Document type definition (DTD) files kept at separate locations.
- Special Declarations if any
Let us understand this with an example.
<?xml version="1.0" encoding= "UTF-8"?> - (1)
<!DOCTYPE car SYSTEM "car.dtd" - (2) and (3) is "car.dtd"
[
<!ENTITY Model SYSTEM "model.xml"> - (4)
<!ENTITY Brand SYSTEM "brand.xml">
]
<car> - (5)
</car>Let us understand each line in the prolog and root element here is the <car>.
Document Declaration
First attribute specifies the current version of the XML document standard, and if you have foreign characters, then XML uses UTF-8 encoding system to display symbols and characters. It called the parser to treat the document as XML document.
Link to DTD
The next line is a link to a DTD file called the cars.dtd and its location is SYSTEM which is local directory of the XML file.
DTD Entities
After link to DTD fil, we have declared the two DTD entities and fifth line is the root element. The prolog is up to the root element, and it is optional.
The Tree View
Earlier we mentioned about the tree view of the document and discuss how elements and tags divide the document into different parts in a tree like structure. In this tree view, circle represents the elements and boxes are content of the elements.
The tree always starts from top with a root element. Consider the following XML document and its tree view. Each of the tag /element is like a box that contains other elements and their content. This is the basis for document tree structure in XML.
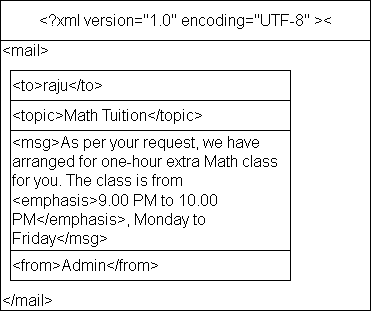
You can see that the elements are nested where <mail> is the root of the tree that set the boundaries for the document. The root contains all the elements called its children and contents are the lowest in the tree called the leaves. For a leaf node, all other nodes above it is its ancestors, and they are the descenders, starting from the root.
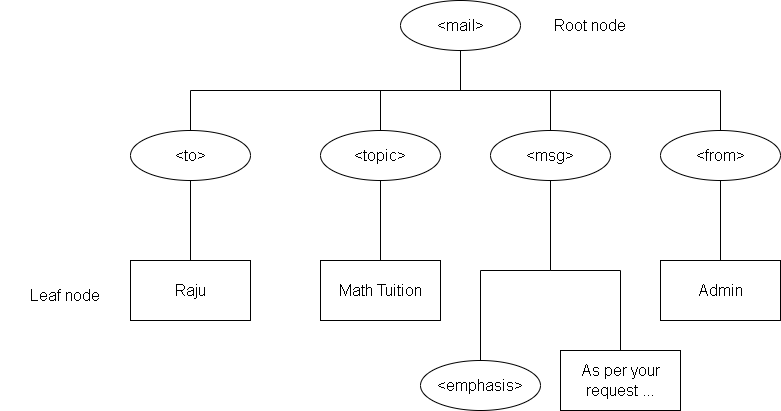
Note the hierarchy that starts with the root node <mail> and all the content of each element/tag is the leaf node depicted using a rectangular box.
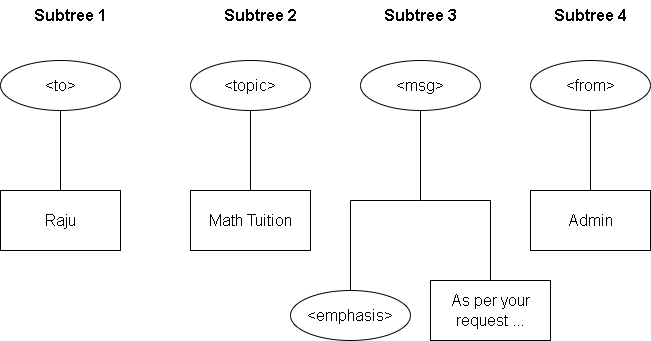
Siblings and Subtrees
The root has multiple child nodes, and they are at the same level. The relationship between them is of siblings. For instance, the tag <to> and <from> are siblings’ nodes.
Each of these siblings have children that makes another hierarchy called a subtree. Its structure is similar to that of root and its child nodes.
Therefore, we have four subtrees from the above tree view, one for each child node of the root.
Summary
In this article, you learned that the XML document has nested regions called the tags made of element. The element describes the structure of the document which tree like. You can understand this by turning you XML document into a tree diagram.